
I needed to fix scannos in tens of thousands of line-based text files, so I built a tool called Okapi on top of ripgrep to let me find them in context and fix them in bulk using my text editor. Install it with homebrew.
The project is digitizing tens of thousands of pages of US Government employee data. It’s called the Official Register, and there are over 100 volumes spanning 150 years. I’ve had great success with olmOCR, as it’s far more accurate than vanilla Tesseract. But it still generates many, many scannos.
Double-U Double-U III #
An example of a really common character sequence produced by the OCR which is almost never right is III. In a few rare cases, that really does mean that the person has the same name as his father and grandfather. But the text I was working on looked like this:
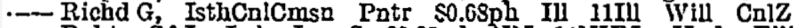
That means that Richard worked for the Isthmian Canal Commission as a Painter for 68¢/hr. He was born in Illinois, was appointed to his position (hired) in the 11th Congressional District of Illinois, county of Will, and stationed in the Panama Canal Zone. (This is from page 144 of the 1909 edition, volume 1.)
As you can see, there can be an awful lot of “vertical line” characters! This is a bit of a stress test for any OCR, and the image quality didn’t help matters. Suffice it to say, III in my dataset is almost always a scanno. Here are just a few examples:
| OCR text | Corrected text |
|---|---|
RosedaleIII |
RosedaleIll |
Rock IslandArsnIllIII |
RockIslandArsnlIll |
RockIsland ArsmllIII |
RockIslandArsnlIll |
IIIllaSalle |
IllLaSalle |
2IIIISangamon |
21IllSangamon |
IIIpr |
Hlpr |
NIIIVS |
NHDVS |
And there are many more permutations. Really, III is an indicator that something is wrong with the text. Just blindly replacing it with Ill would fix some cases, but it would often generate incorrect text and would actually serve to make other scannos lurking nearby that much harder to find.
Finding strings of interest by regex using ripgrep was good, but it was still much too slow. Sometimes there are hundreds of matches, I couldn’t be opening these files one at a time to figure out the context and edit/save a line or two. I needed the precision of regex combined with the power of a text editor.
Enter Okapi:
$ okapi III
$ okapi "Dan[^l ]\b" # Should probably be the abbreviation "Danl"
$ okapi "Mich\wl" -e "Michel" # Pass an exclude pattern
$ okapi Fli -c ..15 # Restrict matches to the first 15 charsNow I can edit similar errors across files without needing to know exactly what the replacement string is. I can have a page of matches visible at a glance. I can also use the full power of multi-select. Asciinema demos notwithstanding, I am using Sublime’s multi-select features to grab every instance of some subset pattern and change them all at once. Then I can surgically find and change another subset. Once I’m done, everything is saved back to disk.
Here’s what the edit buffer looks like:
# --- Begin editable lines ---
A 76 ▓ — Richd G, IsthCnlCmsn Pntr $0.65ph Ill 11Ill Will CnlZ
B 22 ░ Richd G, IsthCnlCmsn Clk $125pm Eng 5GaFulton CnlZ
B 40 ░ Mrs Rosa J, Treas PrtnrsAsst Engrv&Prntg $1.50pd DC DC DC
# --- File Aliases ---
# A = /Users/nick/offreg/olmocr/1909/150-column_0.md
# B = /Users/nick/offreg/olmocr/1909/708-column_1.mdI was inspired by git’s interactive rebase interface. The alias letters in the first column tie the line to its file. Then there’s the line number and a separator character which also visually breaks the lines up by file. The aliases are limited to 3 uppercase alpha characters right now, but that still gives one over 18,000 files. That ought to be enough for anybody!
Text, Meet Image #
Having all the matching lines in a single buffer is a major step forward, but in my case it wasn’t enough. I also needed a way to show the original image right under the text for a given line. That would let me see the ground truth with maximum efficiency. For example, Wrn should clearly be Wm. But something like the prefix Fli is ambiguous. In some cases, this should be Eli (Elizabeth). But equally correct might be Fli (Flin) or Ell (Ella). Context is key.
Here’s the strategy I used:
- Each column image is run through Tesseract. Yes, this is a second, lower-quality OCR. But it has one major advantage: the line results come with bounding boxes.
- The Tesseract data is precomputed and saved to a JSON file next to the image.
- I’ve built another Rust tool which, given a text file in the corpus and a line number, does a fuzzy match between the contents of that line and all the Tesseract lines. It normalizes the strings first and uses a trigram match, identifying the best match.
- Once it has the bounding box, it loads the column image and returns the region of interest as a UUEncoded string.
- I have a Sublime plugin which calls the Rust tool every time the cursor changes line in an Okapi file and displays it in an HTML overlay.
And guess what? It works!

Feedback welcome #
If you’d like more information, please get in touch. I’m happy to accept Issues or PRs in the Okapi repo. The database of names isn’t online yet, but that is coming soon!